HaToDb - A demonstration on storing historical node data to a database
16.04.2020
Introduction
During the past years, we have received many requests from our customers for an introduction to data transfer from historical databases offering OPC UA Historical Access to their upper-level systems, such as MES, ERP and Big Data systems. This blog post will provide you with an overview of an implementation, along with code snippets demonstrating the crucial parts. We hope it will give you insight on how to create something similar suited to your needs using our SDK for Java product.
Technical overview
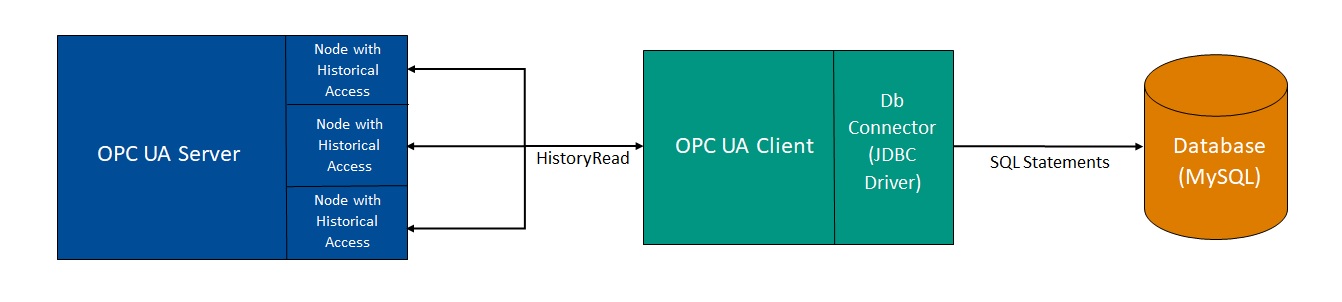
The picture above depicts the high-level implementation of the application.
Our underlying server on the left depicts a server containing nodes from which we wish to store values to a given database. It is achieved by creating an OPC UA client using the Prosys OPC SDK for Java, which retrieves values from the underlying server and stores them into the database.
The program flow of the application can be broken down into the following steps:
-
Read configuration file containing information, such as connection address of underlying OPC UA server, and the database.
-
Parse file containing NodeIds to know which nodes should be polled for value changes
-
Create necessary database tables and connection
-
Read all specified node values using UaClient and insert them into the database at a fixed rate.
To communicate with the underlying server, we instantiate the UaClient class and connect it to the given server address:
import com.prosysopc.ua.client.UaClient;
...
private UaClient client = new UaClient();
client.setAddress(serverAddress);
try{
client.connect();
}
catch(ServiceException e){
e.printStackTrace();
}As for the database connection, we use the MariaDB jdbc Driver:
Class.forName("org.mariadb.jdbc.Driver")
.getDeclaredConstructor().newInstance();
Connection dbConnection = DriverManager
.getConnection(dbUrl); To read the nodes at a fixed rate, we create a Runnable function is called at specified rate:
Runnable readNodesRunnable = () -> {
try{
readNodes(monitoredIds);
}
catch(Exception e) {
e.printStackTrace();
}
};
ScheduledExecutorService pollService =
Executors.newSingleThreadScheduledExecutor();
pollService
.scheduleAtFixedRate(readNodes, 0, pollrate,
TimeUnit.MILLISECONDS);The readNodes(monitoredIds) goes through the list of NodeIds whose historical values are to be read and stored.
First, we want to make sure that the given node exists in the AddressSpace and remove it from the monitored nodes list in the case that it doesn’t:
for (NodeId monitoredId : monitoredIds) {
UaVariable
monitoredVariable;
try {
monitoredVariable =
(UaVariable) client
.getAddressSpace()
.getNode(monitoredId);
} catch (AddressSpaceException e) {
logger.error(
"Monitored nodeId "
+ monitoredId
+ " does not exist in server");
printException(e);
monitoredIds.remove(
monitoredId);
continue;
}Additionally, we need to make sure the node supports HistoryRead before attempting to fetch historical values.
boolean hasHistoryAccess;
AccessLevelType accessLevels =
monitoredVariable.getAccessLevel();
AccessLevelType userAccessLevels =
monitoredVariable.getUserAccessLevel();
hasHistoryAccess =
accessLevels.contains(
AccessLevelType.Fields.HistoryRead)
&&
userAccessLevels.contains(
AccessLevelType.Fields.HistoryRead);To fetch a historical data for a variable, we need to define a timeframe between which values are fetched. By default, the timestamp of the most recent value available for a given node in the database is used as a starting point, and all values are fetched until the current moment. However, our implementation also allows the user to decide, whether results should be fetched from the last available database entry, or for example, from the last 10 seconds.
If no entries can be found for the given node, we fetch Historical results from the server based on a user-defined starting point.
DateTime startTime;
DateTime endTime;
endTime = DateTime.fromMillis(DateTime.currentTime()
.getTimeInMillis());
if (hasHistoryAccess) {
lastEntryStatement.setString(1,
monitoredId.getValue().toString());
ResultSet results = lastEntryStatement.executeQuery();
results.beforeFirst();
if (results.next()) {
long resultMillis =
results.getTimestamp(2).getTime();
long currentMillis =
System.currentTimeMillis();
if (startFromLastEntry
|| resultMillis >= currentMillis - (pollrate * 2)) {
startTime = DateTime
.fromMillis(resultMillis);
}
else {
startTime = DateTime.fromMillis(
endTime.getTimeInMillis() - 10000);
}
}
else {
startTime = chosenTime;
}
values = client
.historyReadRaw(monitoredId, startTime,
endTime,
UnsignedInteger.valueOf(1000), true,
null, TimestampsToReturn.Source);Now that we have fetched all the values of the given node, their values can be added as entries into the database.
for (DataValue value: values){
String valueString = value.getValue().toString();
//Insert into db...
}Summary
In this article, we took a look at how historical variable node values can be aggregated and stored from an underlying OPC UA server into a database, such as MariaDB. As we mentioned at the beginning, this topic has been a point of interest for many of our customers. We hope this blog post covered all the possible dark spots and answered occurred questions. Sections of the code snippets used in this post are part of our framework product. Our software services also constantly provide our customers with turn-key solutions based on our framework products. For any further information and any commercial questions, please contact our sales team.

Luukas Lusetti
Software Engineer
Email: luukas.lusetti@prosysopc.com
Expertise and responsibility areas: OPC & OPC UA product development and project work
Tags: OPC UA, Historian, SDK for Java, Java, Demo
comments powered by DisqusAbout Prosys OPC Ltd
Prosys OPC is a leading provider of professional OPC software and services with over 20 years of experience in the field. OPC and OPC UA (Unified Architecture) are communications standards used especially by industrial and high-tech companies.
Newest blog posts
Why Do Standards Matter in Smart Manufacturing?
The blog post discusses the importance of standards in smart manufacturing, envisioning a future where auto-configurable systems in manufacturing rely on standardized data formats for seamless integration and reduced costs, with a focus on the OPC UA standard family as a key enabler.
OPC UA PubSub to Cloud via MQTT
Detailed overview of the demo presented at the OPC Foundation booth
SimServer How To #3: Simulate data changes on a server using an OPC UA client
A two-part step-by-step tutorial on how to write data changes on an OPC UA server using an OPC UA client.